经典卷积神经网络
1、AlexNet(2012)
ImageNet Classification with Deep Convolutional Neural Networks
主体贡献:
- 提出了卷积层加全连接层的卷积神经网络结构
- 首次使用ReLU函数作为神经网络的激活函数
- 首次提出Dropout正则化来控制过拟合
- 使用加入动量的小批量梯度下降算法加速了训练过程的收敛
- 使用了数据增强策略极大地抑制了训练过程的过拟合
- 利用了GPU的并行计算能力,加速了网络的训练与推断
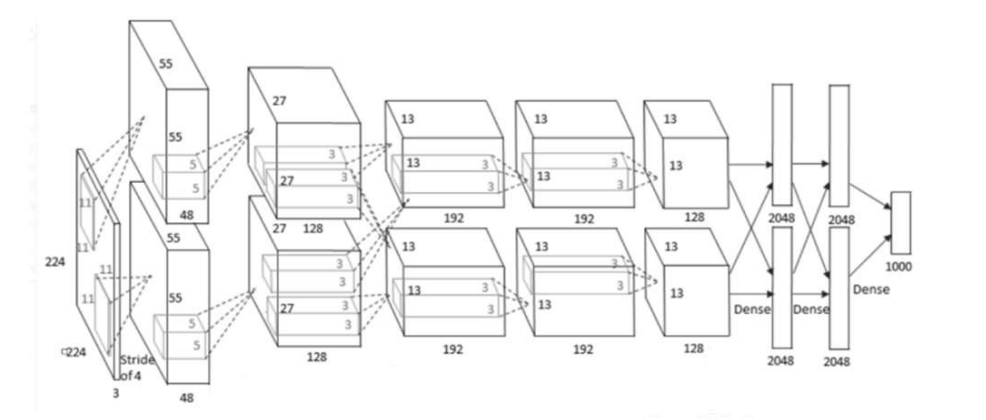
1 | 输入为3*224*224 输出: 参数量: 计算量(FLOPS): |
值得注意的一点:原图输入224 × 224,实际上进行了随机裁剪,实际大小为227 × 227。
卷积层参数量计算公式:卷积核高* 卷积核宽* 输入通道数* 输出通道数
卷积层计算量计算公式:输出feature map的高* 输出feature map的宽* 输出feature map的通道数* 卷积核高* 卷积核宽* 输入通道数
LRN,局部响应归一化层,作用是对局部神经元的活动创建竞争机制;响应比较大的值变得相对更大;抑制其他反馈较小的神经元;增强模型的泛化能力;计算公式如下:
$$
b_{xy}^i = a_{xy}^i / (k + α∑_{j=max(0,i-n/2)}^{min(N-1,i+n/2)} (a_{xy}^j)^2) ^ β
$$
其中:
$$\alpha_{xy}^i$$: ReLU处理后的神经元,作为LRN的输入
$$b_{xy}^i$$: LRN的输出,LRN处理后的神经元
N:kernal总数或通道数
$k$、$n$、$\alpha$、$\beta$:常量,超参数,k类似于bias,n对应于Caffe中的local_size,在论文中这几个值分别为2、5、1e-4、0.75。
2、ZFNet
主要改进: 错误率由16.4%–>11.7%
将第一个卷积层(11* 11滤波器,s=4)的卷积核大小改为了7* 7,s=2;
将第二、第三个卷积层的卷积步长都设置为2
conv3、4、5的卷积核个数改为512、1024、512
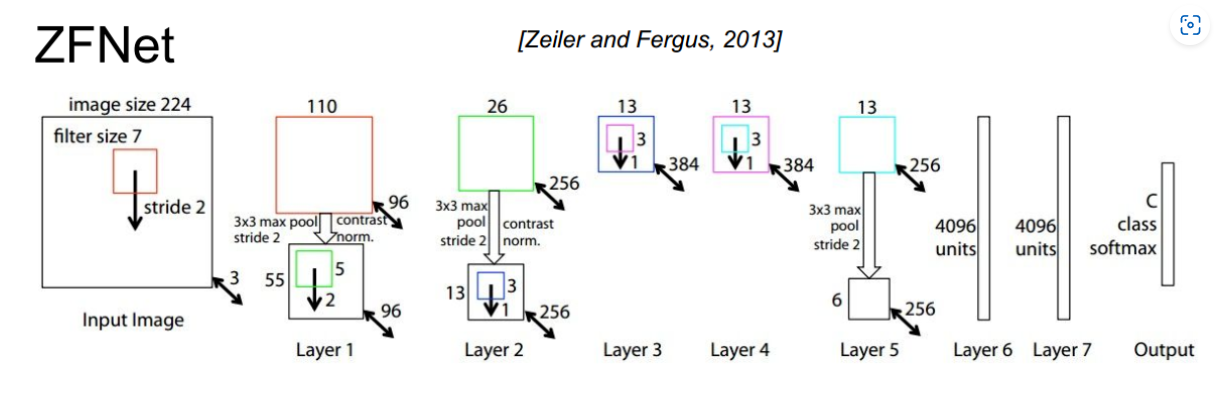
1 | 输入为3*224*224 输出: 参数量: 计算量(FLOPS): |
ZFNet的主要研究贡献:
(1)特征可视化:利用反卷积、反池化、反激活函数去反可视化feature map,通过feature map可以看出特征分层次体系结构,以及我们可以知道前面的层学习的是物理轮廓、边缘、颜色、纹理等特征,后面的层学习的是和类别相关的抽象特征。这一个非常重要的结论,我们后面很多的微调手段都是基于此理论成果。再次强调这个结论:
结论一:CNN网络前面的层学习的是物理轮廓、边缘、颜色、纹理等特征,后面的层学习的是和类别相关的抽象特征
结论二:CNN学习到的特征具有平移和缩放不变性,但是,没有旋转不变性
(2)特征提取的通用性:作者通过实验说明了,将使用ImageNet2012数据集训练得到的CNN,在保持前面七层不变的情况,只在小数据集上面重新训练softmax层,通过这样的实验,说明了使用ImageNet2012数据集训练得到的CNN的特征提取功能就有通用性。
- 结论三:CNN网络的特征提取具有通用性,这是后面微调的理论支持
(3)对于遮挡的敏感性:通过遮挡,找出了决定图像类别的关键部位当,在输入图片中遮挡了学习到的特征时,分类效果会很差。同时根据遮挡图像局部对分类结果的影响来探讨对分类任务而言到底那部分输入信息更重要。
(4)特征的层次分析:作者通过实验证明了,不同深度的网络层学习到的特征对于分类的作用,说明了深度结构确实能够获得比浅层结构更好的效果。 通过实验,说明了深度增加时,网络可以学习到更具区分的特征。 底层特征在迭代次数比较少时就能收敛,高层需要的迭代次数比较多 越是高层的特征,其用来做分类的性能越好
3、VGGNet(2014)
论文:Very deep convolutional networks for large-scale image recongnition

其中卷积核均为3*3的,步长为1,padding也为1,卷积不改变图像尺寸,只在最大池化层设置2 *2,步长为2,每经过一层pool,图像高宽减半,通道数不变;全连接层使用了dropout策略。
网络结构中全部采用3* 3卷积核级联,放弃采用大卷积核,理由是在获得相同大小的感受野的情况下,3* 3的小卷积核级联比大卷积核的参数更少、计算量更小,同时网络更深、更非线性。
为什么VGG网络前四段里,每经过一次池化操作,卷积核个数就增加一倍?
- 池化操作可以减小特征图尺寸,降低显存占用
- 增加卷积核个数有助于学习更多的结构特征,但会增加网络参数量以及内存消耗(这也就是为什么第五段没有继续增加卷积核个数,减少参数,也防止过拟合)
- 一减一增的设计平衡了识别精度与存储、计算开销
4、GoogLeNet(2014)
主要创新点:
- 提出了一种Inception结构,能够保留输入信号中的更多特征信息;
- 去掉了AlexNet的前两个全连接层,并采用了平均池化,这一设计使得GoogLeNet只有500万参数,比AlexNet少了12倍;
- 在网络的中部引入了辅助分类器,克服了训练过程中的梯度消失问题。
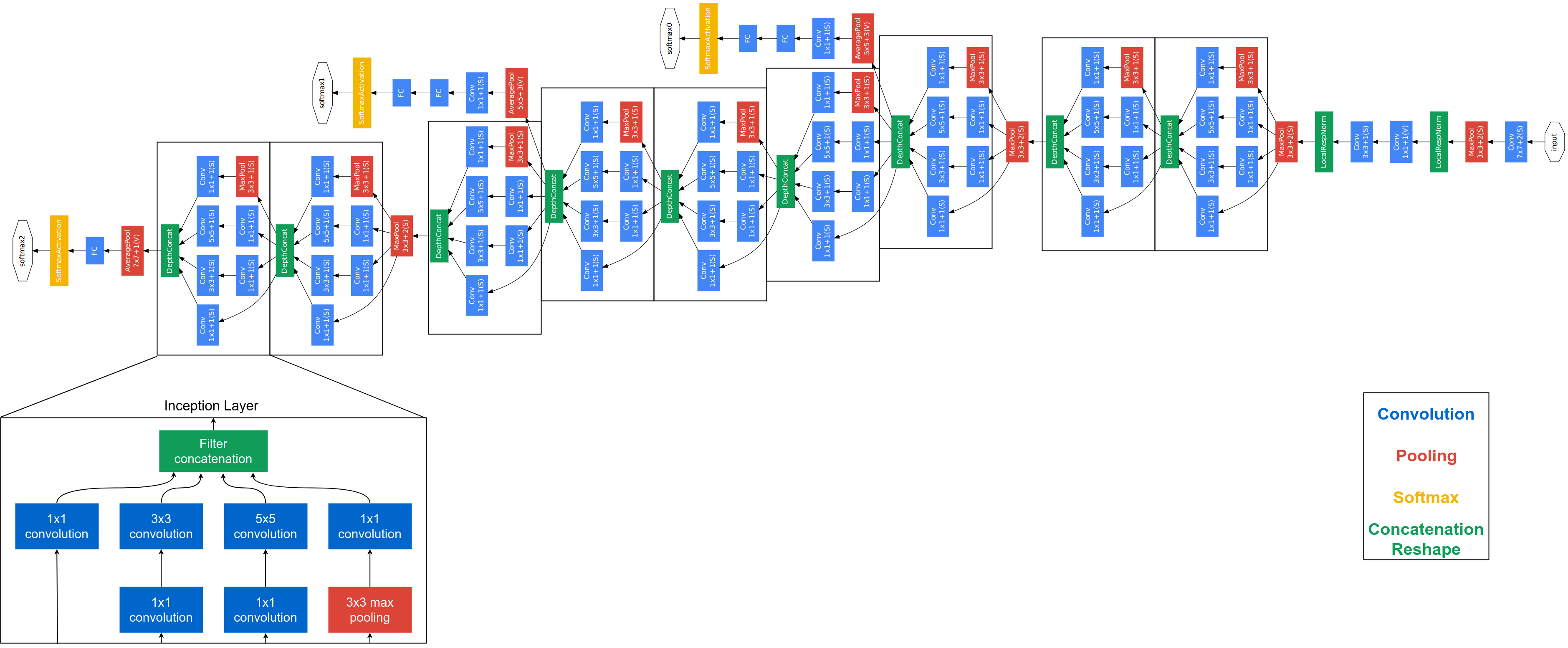
网络主体部分由9个Inception模块构成,在第三个、第六个Inception模块分出两个辅助分类器,帮助底层神经网络参数更新,避免梯度消失。训练的时候,3个分类器一起参与训练,相当于有3个梯度流,最底层梯度为3个梯度流的和,有助于底层参数的更新。但推理时只采用最后一个分类器的输出。
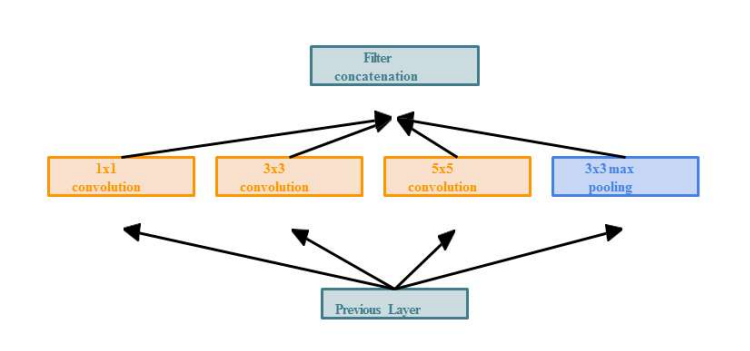
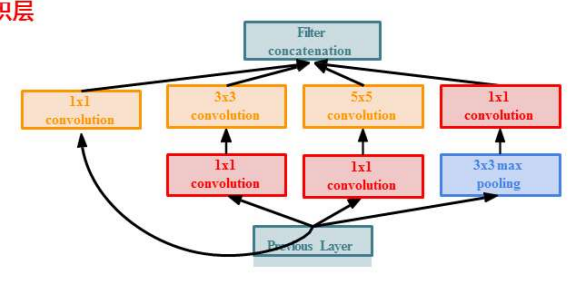
Inception模块对输入分出四个分支,不改变图像高宽,只改变通道数,然后将四个分支在通道维拼接起来作为输出。对输入,采用1* 1卷积降维,再3* 3卷积升维。(1* 1卷积减少通道数并不会丢失信息)
GoogLeNet分类器最后采用的是平均池化层,丢失了语义结构的位置信息,有助于提升卷积层提取到的特征的平移不变性。
5、ResNet(2015)
论文: Deep Residual Learning for Image Recognition, Identity Mappings in Deep Residual Networks
主要创新:
提出了一种残差模块,通过堆叠残差模块可以构建任意深度的神经网络,而不会出现“退化”现象
提出了批归一化方法来对抗梯度消失,该方法降低了网络训练过程对于权重初始化的依赖
提出了一种针对ReLU激活函数的初始化方法
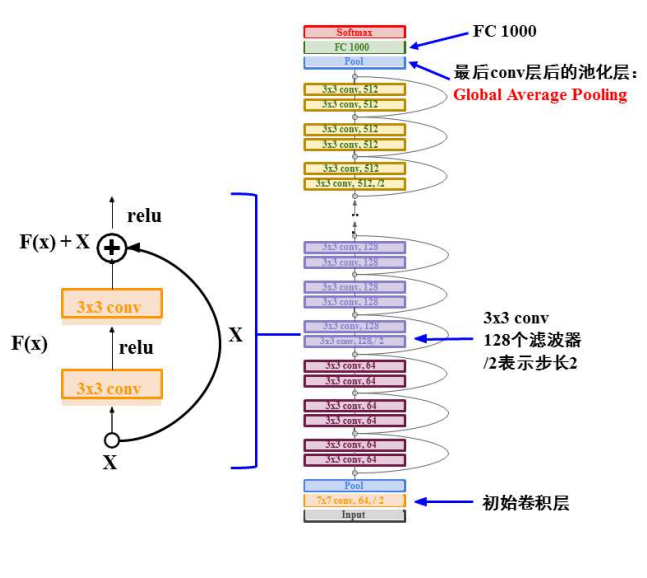
残差结构,输入为$x$,输出为$H(x)$,而$H(x)=F(x)+x$,所以$F(x)=H(x)-x$,因此称$F(x)$为残差。
完整ResNet架构:初始卷积层、堆叠残差块、每个残差快有2个3* 3卷积层、周期性使用步长2的卷积,将特征响应图高宽减少一半、只有fc1000用于输出类别
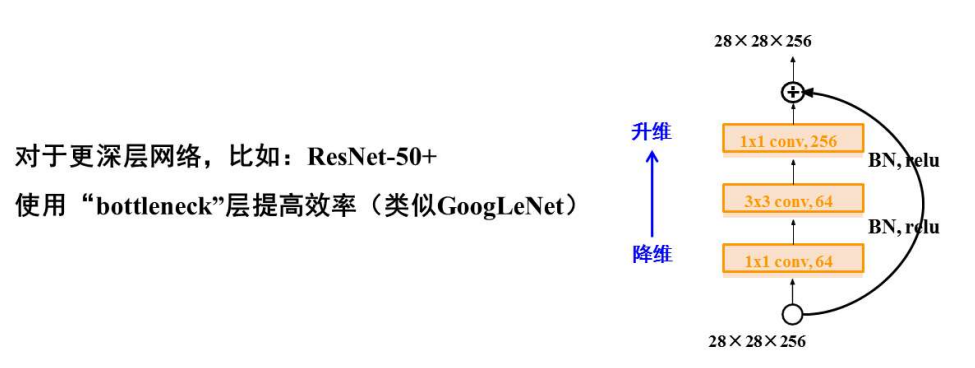
为什么残差网络性能这么好?一种典型的解释:残差网络可以看作一种集成模型
6、R-CNN
实现流程示意如下:
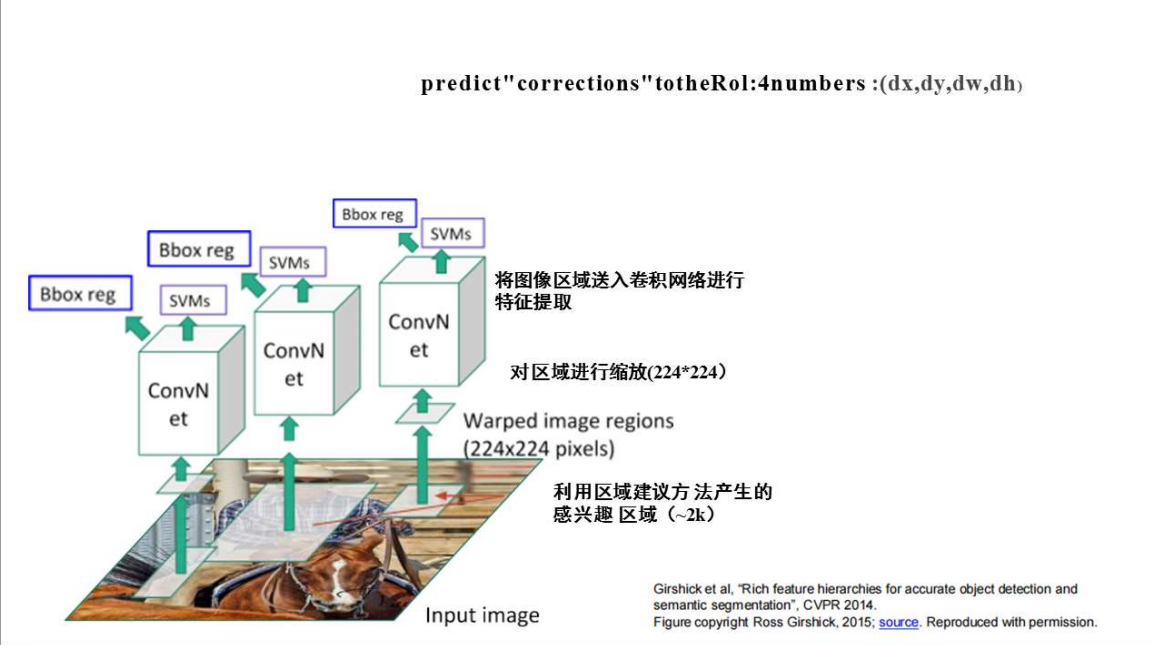
6.1、区域建议:Selective Search
对于region proposal的要求:
- 找出所有潜在可能包含目标的区域
- 运行速度需要相对较快,比如,Selective Search在CPU上仅需要运行几秒钟就可以产生2000个候选区域
这一步的实现方式有很多,最容易想到的就是穷举法,在图片上使用穷举法或者滑动窗口选出所有物体可能出现的区域框,就是在原始图片上进行不同尺度不同大小的滑窗,获取每个可能的位置。而这样做的缺点也显而易见,复杂度太高,产生了很多的冗余候选区域,而且由于不可能每个尺度都兼顾到,因此得到的目标位置也不可能那么准,在现实当中不可行。因此提出了Selective Serch算法,SS算法的具体流程如下:
- 使用《Efficient Graph-Based Image Segmentation》中的方法初始化区域集 $R$
- 计算 $R$ 中相邻区域的相似度,并以此构建相似度集$S$ (初始化区域中 $\forall r_i和r_j (\in R)$之间的相似度组成的集合;
- 如果 $S$ 不为空,则执行以下7个子步骤,否则,跳至步骤4;
- 获取 $S$ 中的最大值 $s(r_i,r_j)$ (表示 $r_i与r_j$之间的相似度);
- 将 $r_i$ 与 $r_j$ 合并成一个新区域 $r_t$ ;
- 将 $S$ 中与 $r_i$ 有关的值 $s(r_i,r_*)$ 剔除掉;
- 将 $S$ 中与 $r_j$ 有关的值 $s(r_*,r_j)$ 剔除掉;
- 使用步骤2中的方法,构建 $S_t$ ,它是 $S$ 的元素与 $r_t$ 之间的相似度构成的集合;
- 将 $S_t$ 中的元素全部添加到 $S$ 中;
- 将 $r_t$ 放入 $R$ 中。
- 将 $R$ 中的区域作为目标的位置框 $L$ ,这就是算法的执行结果。
相似度的计算
- 颜色相似度 $S_{color}(r_i,r_j)$:论文中将每个region的像素按不同颜色通道统计成直方图,其中,每个颜色通道的直方图为25 bins(比如,对于0-255的颜色通道来说,就每隔9(255/9=25 个数值统计像素数量)。这样,三个通道可以得到一个75维的直方图向量 $C_i=c_i^1,\dots,c_i^n$ ,其中n=75。之后,使用 $L1$ 范数(绝对值之和)对直方图进行归一化。由直方图我们就可以计算两个区域的颜色相似度:
$$
S_{color}(r_i,r_j)=\sum\limits_{k=1}^nmin(c_i^k,c_j^k)
$$
其中n=75,表示直方图中的bins,$c_i^k$ 表示 $r_i$ 中像素值为 $k$ 的像素个数,$c_j^k$ 表示 $r_j$ 中像素值为 $k$ 的像素个数。
2、纹理相似度($S_{texture}(r_i,r_j)$ :对每一个颜色通道,在8个方向上提取高斯倒数 ($\sigma$ =1)(先对图像进行高斯滤波,然后在8个方向上进行梯度计算,得到边缘特征)。在每个颜色通道的每个方向上,提取一个bins为10的直方图(每个颜色通道的梯度图像划分为 10 个 bins,计算每个区间的梯度值数量,得到直方图),从而得到每个区域 $r_i$ 的纹理直方图向量 $T_i={t_i^1,\dots,t_i^n}$ ,其中n=240(计算方式:$n_orientations\times bins \times n_channels=8 \times 10 \times 3$ ), $T_i$ 也是用区域的 $L_1$ 范数归一化后的向量。纹理相似度的计算公式:
$$
S_{texture}(r_i,r_j)=\sum\limits_{k=1}^nmin(t_i^k,t_j^k)
$$
3、尺寸相似度($S_{size}(r_i,r_j)$ :优先合并小的区域,如果仅仅是通过颜色和纹理特征合并的话,很容易使得合并后的区域不断吞并周围的区域,后果就是多尺度只应用在了那个局部,而不是全局的多尺度。因此我们给小的区域更多的权重,这样保证在图像每个位置都是多尺度的在合并。
$$
S_{size}(r_i,r_j)=1-\frac{size(r_i)+size(r_j)}{size(im)}
$$
4、填充相似度($S_{fill}(r_i,r_j)$ :填充相似度主要用来测量两个区域之间 fit 的程度,个人觉得这一点是要解决文章最开始提出的物体之间的包含关系(比如:轮胎包含在汽车上)。在给出填充相似度的公式前,我们需要定义一个矩形区域 $BB_{ij}$ ,它表示包含 $r_i$ 和 $r_j$ 的最小的 bounding box。基于此,我们给出填充相似度的计算公式为:
$$
S_{fill}(r_i,r_j)=1-\frac{size(BB_{ij})-size(r_i)-size(r_j)}{size(im)}
$$
为了高效地计算 $BB_{ij}$ ,我们可以在计算每个region 的时候,都保存它们的 bounding box 的位置,这样,$BB_{ij}$ 就可以很快地由两个区域的 bounding box 推出来
5、总相似度计算公式:综合上面四个子公式,我们可以得到计算相似度的最终公式:
$$
S(r_i,r_j)=a_1S_{color}(r_i,r_j)+a_2S_{texture}(r_i,r_j)+a_3S_{size}(r_i,r_j)+a_4S_{fill}(r_i,r_j)
$$
其中,$a_i$ 的取值为0或1,表示某个相似度是否被采纳。
6.2、特征提取
对6.1中提取出的ROI(region of interest),采用诸如AlexNet、VGG、ResNet等网络来提取特征,获得相应的feature map
6.3、分类和边界框回归
根据特征提取得到的feature map,使用SVM作为分类器(SVM分类器的个数由数据集类别数目决定),边界框位置和高宽等信息由Bbox reg得到。
问题在于,对于每一张图片,大约有2k个区域需要卷积网络进行特征提取,重复区域反复计算,计算效率低下。
7、Fast R-CNN
关键改进,放弃先对原始图像Selective Search,生成多个ROI,然后对每个ROI卷积进行特征提取,这样计算重复多,计算效率低,改为先对原始图像进行特征提取(如AlexNet、VGG、ResNet等),然后在得到的feature map上进行Selective Search,生成ROI,然后对生成的ROI进行裁剪+缩放特征来进行尺度的统一(比如暴力resize、按原始比例resize后pad等),然后送入全连接层,进行分类和边界框预测回归。
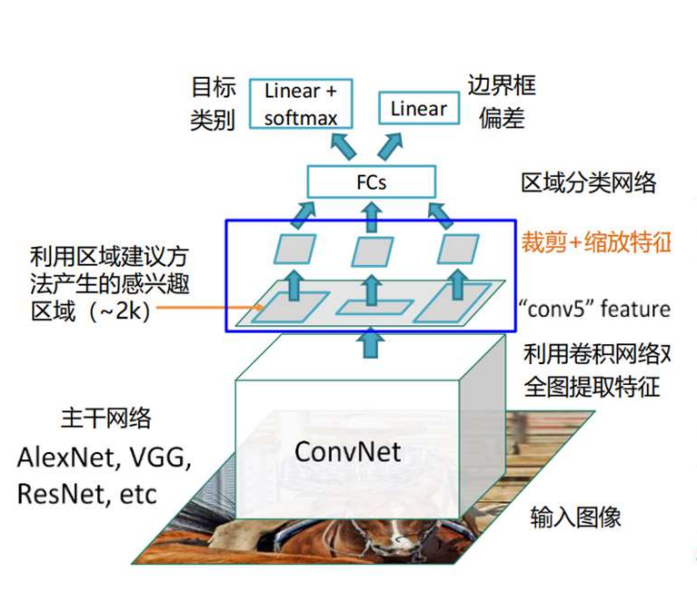
裁剪+缩放特征的实现
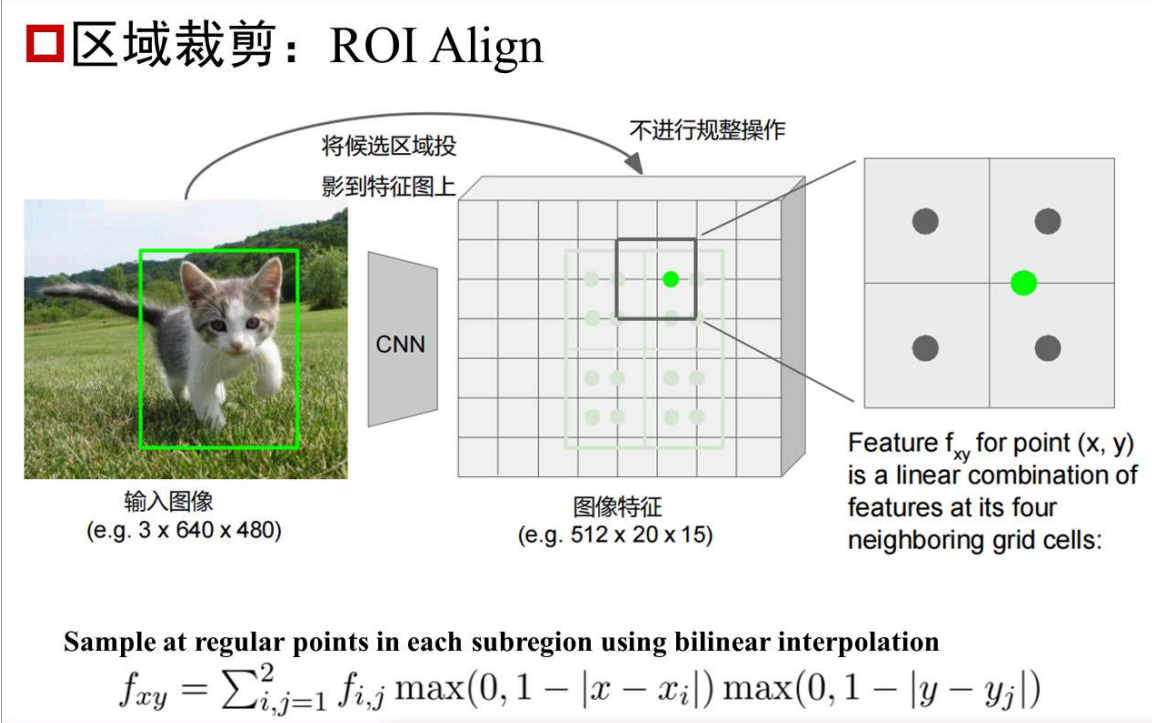
将候选区域投影到特征图上后,得到的区域大概率不规整,四个角点没有刚好落在像素点上,此时没有直接将四个角点规整到最近的像素点(这样可能导致后面最大池化时四个区域不相等,为池化操作带来麻烦),而是将该区域平均分为4个小区域,然后在每个小区域内等间距取4个像素点,当然这四个像素点也大概率不规整,因此采用双线性插值方法得到这些像素点的像素值,然后再对整个区域进行2* 2最大池化,然后进入全连接层。
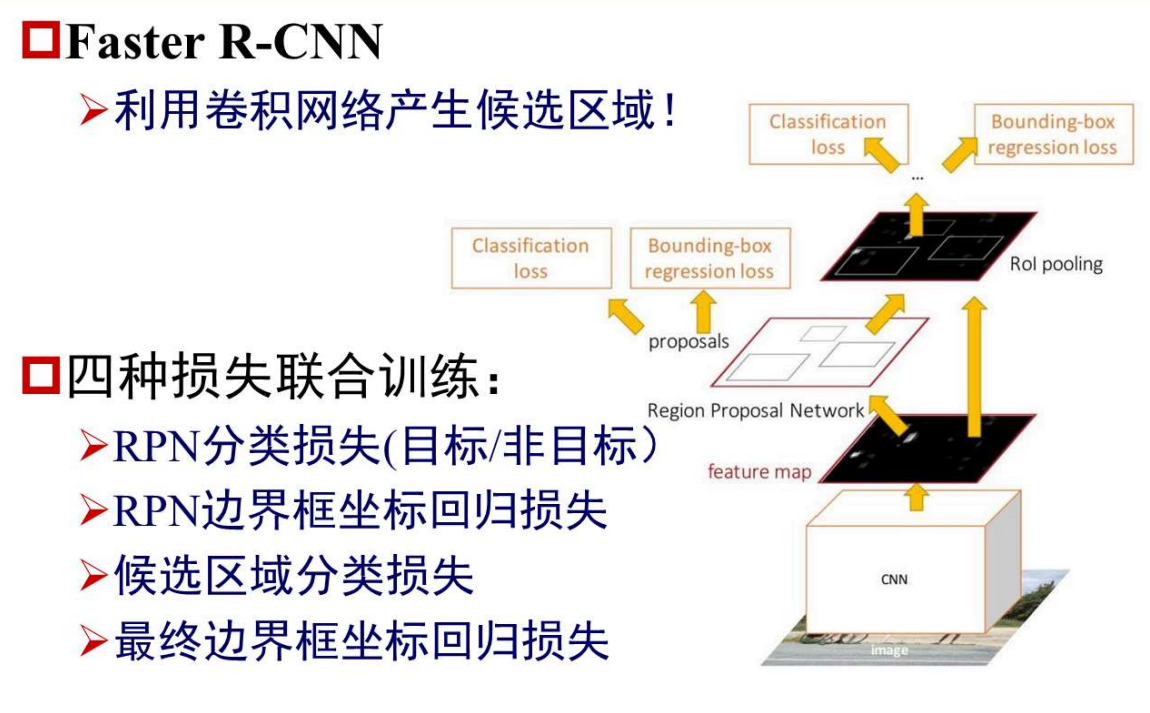
8、Faster R-CNN
主要改进,引进了区域建议网络RPN (Region Proposal Network)来产生候选区域(原因是Selective Search算法提出候选区域占据了整个训练和测试的绝大部分时间),因此提出RPN,使用卷积神经网络来产生候选区域。其他部分与Fast R-CNN一致,即扣取每个候选区域的特征,然后对其进行分类。
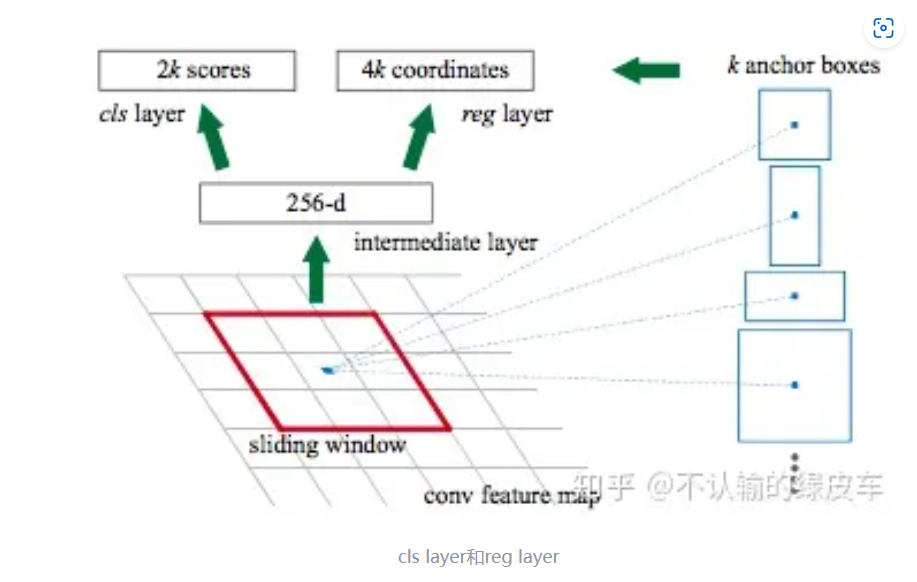
RPN
RPN在结构中是用来生成一系列proposals的一层,本质上它是Backbone的最后一层卷积层作为输入,proposal的具体位置作为输出的神经网络。RPN主要包含以下几步:
- 生成anchor boxes;
- 判断anchor boxes包含的是前景还是背景;
- 回归学习anchor boxes和ground truth的标注的位置差,来精确定位物体。
首先介绍下什么是anchor和anchor boxes。每个anchor点就是backbone网络最后一层卷积层feature map上的元素点。而anchor boxes是以anchor为中心点而生成的一系列框boxes。一个anchor对应的框的具体数量是由scales和aspect ratios 2个参数控制。scales指的是对于每种形状,框体最长边的像素大小,aspect ratios指的是具体由哪些形状,描述的是长宽比。所以scales[8,16,32] 和ratios [0.5,1,2]就代表一个anchor会生成9个anchor boxes。注意的是anchor boxes的坐标是对应在原图尺寸上的,而feature map相比原图是缩小很多倍的,比如VGG16,backbone网络出来的图片尺寸比原图缩小了16倍,如果在原图中采anchor boxes,就需要按16像素点跳着采样。
有了anchor boxes还不够,这些框体大多都都没有包含目标物体,所以我们需要模型学习判断box是否包含物体(即是前景图片还是背景图片),同时对于前景图片我们还要学习来预测box和GT的offset。这2个任务分别是用2个卷积网络实现的,如下图所示,
RPN的损失函数如下,由分类损失和定位损失两部分组成
$$
L(p_i,t_i)=\frac{1}{N_{cls}} \times \sum L_{cls}(p_i,p_i^*) + \frac{\lambda}{N_{reg}} \times \sum p_i^L_{reg}(t_i,t_i^)
$$
其中 $L_{cls}$ 常用交叉熵损失函数,$L_{reg}$ 常用平方误差损失函数
参考链接:ZF网络架构深度详解-CSDN博客
[[1409.1556] Very Deep Convolutional Networks for Large-Scale Image Recognition (arxiv.org)]:



